
rrimyuu 님의 블로그
Paper review | OpenXAI: Towards a Transparent Evaluation ofPost hoc Model Explanations 본문
Neuroscience/Artificial Intelligence
Paper review | OpenXAI: Towards a Transparent Evaluation ofPost hoc Model Explanations
rrimyuu 2024. 8. 7. 15:22논문 링크: https://proceedings.neurips.cc/paper_files/paper/2022/file/65398a0eba88c9b4a1c38ae405b125ef-Paper-Datasets_and_Benchmarks.pdf
부록 링크:
https://proceedings.neurips.cc/paper_files/paper/2022/file/65398a0eba88c9b4a1c38ae405b125ef-Supplemental-Datasets_and_Benchmarks.pdf
1. Introduction
- 예측 모델이 점점 더 중요 분야(예: 의료, 법률, 금융)에 배치됨에 따라, 이러한 모델의 예측 결과를 의사 결정자(예: 의사, 판사)에게 설명하는 것에 대한 중요성 증가
- 이를 위해 최근 문헌에서는 복잡한 기계 학습 모델이 만든 개별 예측에 대한 사후 설명을 생성하는 다양한 기술들이 제안되었음.
- 이러한 지역적 설명 방법 중 일부는 모델의 예측에 대한 각 특징의 영향을 출력하며, 따라서 '지역적 특징 기여도 방법' (local feature attribution method) 이라고 불림.
- 이러한 특징 기여도 방법들은 일반성 덕분에 의학, 금융, 법률, 과학 등에서 복잡한 모델을 설명하는 데 점점 더 많이 사용되고 있음. 따라서 이러한 방법들이 생성하는 설명이 신뢰할 수 있도록 보장하는 것이 중요하며, 이를 통해 관련 이해관계자와 의사 결정자들에게 모델의 기초에 대한 신뢰할 수 있는 정보를 제공해야 함.
- 이전 연구들은 설명의 신뢰성 개념인 reliability such as faithfulness (or fidelity), stability (or robustness), fairness and proposed metrics for quantifying these notions 를 제안했음.
- XAI 연구의 진행에 광범위한 영향을 미치는 가장 큰 열린 질문 중 하나는 "어떤 설명 방법이 어떤 신뢰성 개념에 대해 효과적이며 어떤 조건에서 그런가?" 임. 따라서, 체계적이고 재현 가능하며 투명한 방식으로 벤치마킹해야 함. 설명 방법의 다양성이 증가하고, 기존 연구에서 제시된 평가 설정과 지표가 표준화된 오픈 소스 구현 없이 제시됨에 따라, 이러한 벤치마킹 노력을 수행하는 것이 상당히 도전적임.
1.2. Related works
- 이전 연구는 설명의 reliability such as faithfulness (or fidelity), stability (or robustness), fairness 을 연구했음.
1) faithfulness : 주어진 설명이 기본 모델의 실제 행동을 얼마나 충실하게 반영하는지를 측정함.
2) stability : 입력의 작은 변동에 대해 설명이 크게 변하지 않도록 보장함.
3) fairness : 설명의 신뢰성이나 안정성에 그룹 기반 불균형이 없도록 보장함. - 세 가지 개념을 정량화하기 위한 다양한 평가 지표를 제안해왔음.
1) 주요 특징이 데이터 인스턴스에서 삭제되거나 추가될 때 예측된 클래스의 확률 변화를 측정함. 확률의 급격한 변화는 높은 정도의 설명 신뢰성을 의미함.
2) 작은 변동이 주어진 인스턴스에 가해졌을 때 결과 설명의 최대 변화를 통해 안정성을 대략적으로 정량화함.
3) 설명의 공정성을 다수와 소수 그룹 간 인스턴스에서 평균된 신뢰성 (또는 안정성) 지표 차이로 정량화함. - XAI libraries and benchmark
1) Captum : 다양한 최첨단 XAI 구현 및 API 제공 오픈 소스 라이브러리임. 하지만 XAI 방법을 평가하거나 벤치마킹 하지 않음.
2) Quantus : faithfulness and stability/robustness of explanation methods 측정을 위한 특정 평가 지표 구현을 제공함. 하지만 XAI 방법을 벤치마킹하거나 성능 비교 가능한 공개 대시보드를 제공하지 않음. Quantus 에서 지원하는 stability/robustness 는 다소 구식이며 최근 제안된 지표로 대체되었음. fairness 를 지원하지 않음. (의료, 형사, 사법 등서 중요함.)
3) SHAP benchmark : SHAP 의 다양한 변형을 평가하고 비교하는 데 중점. 중요 및 비중요 특징의 변동성 측정 ( Prediction Gap on Important (PGI) 및 Unimportant (PGU)) 지표와 유사함. 하지만 stability/robustness, fairness 지표를 포함하지 않음.
4) XAI bench : faithfulness 를 평가하기 위한 XAI 방법 (LIME, SHAP, MAPLE ...) 의 groundtruth (GT) 설명이 포함된 합성 데이터셋을 구성. 하지만 이들 평가를 신뢰할 수 없으며 합성 데이터셋을 통해 학습된 예측 모델이 GT 을 준수하지 않을 수 있다고 주장. 합성 데이터셋이 실제 데이터셋과 대표성이 없을 수 없으므로 (?) 범위가 제한적.
-> OpenXAI 에서 합성 데이터셋 단점을 해결하는 새로운 합성 데이터셋 생성기 제안.
2. Overviwe of OpenXAI Framework
2.1. Datasets and Predictive Models
- 8개의 다양한 합성 및 실제 데이터셋이 포함되어 있음.
- 합성 데이터셋은 GT 를 구축할 수 있게 하며 이를 통해 XAI methods 가 출력한 explanations 을 평가할 수 있음. (실제 데이터셋은 일반적으로 GT 를 구축하기 어려운 경우가 많음.)
- 지금까지의 합성 데이터셋 생성 방법은 학습된 모델이 데이터셋의 GT를 준수할 거란 보장이 없다는 단점이 입증되었음. (주요 단점) 이는 post hoc explanation 을 GT 를 통해 평가하는 것이 잘못될 수 있음을 의미함.
ex. A, B, C, D라는 합성 데이터셋이 있을 때 GT 가 오직 A, B 특징에만 의존한다고 가정함. 이 데이터를 기반으로 모델을 학습시킴. 이때, A와 B가 각각 C와 D와 상관관계가 있다면 결과 모델은 C와 D를 기반으로 예측할 수 있음. post hoc explanation 로 모델의 가장 중요한 특징이 C와 D라고 나타낼 수 있게 됨. - (합성 데이터셋) 이 문제를 해결하고자 SynthGauss 라는 새로운 합성 데이터 생성 메커니즘을 개발함. 아래와 같이 하면 학습 모델은 데이터의 GT를 준수하게 됨.
- three key properties, namely, feature independence, unambiguouslydefined local neighborhoods, and a clear description of feature influence in each local neighborhood.
- K개 잘 분리된 클리스터를 생성. 각 클러스터의 데이터 포인트는 평균과 공분산 행렬을 가진 가우시안 분포에서 샘플링 됨. 모든 클러스터의 평균을 설정하여 클러스터 내 거리 (intracluster distances) 가 클러스터 간 거리 (intercluster distances) 보다 훨씬 작도록 함. 모든 클러스터의 공분산 행렬을 단위 행렬로 설정함. 이렇게 하면 모든 특징이 "독립적"이며 클러스터가 명확하게 정의됨.
- 각 클러스터에 대해 랜덤으로 feature mask vector (0과 1로 구성된 벡터) (m_k) 를 샘플링하여 인스턴스의 GT label 을 생성함. (값이 1이면 특징이 영향을 미친다는 것을 의미함) 각 클러스터의 인스턴스 레이블링 과정에서 각 특징의 상대적 중요성을 포착하는 feature weight vector (w_k) 를 랜덤으로 샘플링함. 클러스터의 인스턴스 기준 GT 는 개별 인스턴스의 특징 값과 해당 클러스터의 m_k (모든 인스턴스의 GT) 및 w_k 의 내적 함수 (시그모이드 함수) 로 계산됨. - (실제 데이터셋)
- OpenXAI 릴리스에 7개 실제 데이터셋 포함.
- 다양한 실제 도메인(예: 금융, 대출, 의료, 형사 사법 등), 데이터셋 크기(예: 소규모 vs 대규모), 차원(예: 저차원 vs 고차원), 클래스 불균형 비율, 특징 유형(예: 연속형 vs 이산형) 등 여러 측면을 다룬 데이터를 포함.

2.2. Explainers
2.3. Evaluation Metrics
- Include eight different metrics to measure explanation faithfulness (both with and without ground truth explanations), three different metrics to measure stability, and eleven different metrics to measure group-based disparities (unfairness) in the values of the aforementioned faithfulness and stability metrics.
- (Ground-truth Faithfulness) feature contribution 기반 설명 간의 유사성을 포착하기 위한 6가지 평가 지표 제안.
GT 는 합성 데이터에서 사용자가 정의하므로 알 수 있음. (feature mask vectors)
- Feature Agreement (FA) : 주어진 post hoc explanation 과 GT 설명 간의 공통적으로 나타나는 상위 K개의 feature의 비율을 계산함.
- Rank Agreement (RA) : 주어진 post hoc explanation 과 GT 설명 간의 공통적으로 나타나는 상위 K개의 feature의 비율을 계산하며 이 features 들이 각 rank orders 에서 동일한 위치에 있는지 확인.
- Sign Agreement (SA) : 주어진 post hoc explanation 과 GT 설명 간의 공통적으로 나타나는 상위 K개의 feature의 비율을 계산하며 이 features 들이 양쪽 설명에서 동일한 부호 (기여 방향) 을 공유하는지 확인.
- Signed Rank Agreement (SRA) : 주어진 post hoc explanation 과 GT 설명 간의 공통적으로 나타나는 상위 K개의 feature의 비율을 계산하며 이 features 들이 양쪽 설명에서 동일한 부호 (기여 방향) 와 위치 (순위) 를 공유하는지 확인.
- Rank Correlation (RC) : 주어진 post hoc explanation 과 GT 설명 간의 feature order 일치를 측정하기 위해 Spearman 순위 상관계수 계산.
- Pairwise Rank Agreement (PRA) : 주어진 post hoc explanation 과 GT 설명 간에 feature 쌍의 상대적인 순서가 동일한지 포착함. - (Predictive Faithfulness) 모델의 예측 결과와 설명 간의 신뢰성을 측정함. GT explanation 이 없을 때 사용할 수 있는 지표임.
- Prediction Gap on Important Feature Perturbation (PGI) : 주어진 설명에서 중요하다고 간주되는 features 들을 perturbation 했을 때 예측 확률 차이를 측정. 모델 예측에 큰 영향을 미치는 features 를 변경했을 때 예측 확률이 많이 변하면 PGI 값이 커지며 설명의 신뢰성을 높게 봄.
- Prediction Gap on Unimportant Feature Perturbation (PGU) : 중요하지 않다고 간주되는 features 들을 perturbation 했을 때 예측 확률의 차이를 측정함. 중요하지 않은 features 를 변경했을 때 예측 확률이 적을 수록 PGU 값이 작아지며 설명이 해당 features 가 중요하지 않다는 것을 잘 반영한다고 볼 수 있음. - (Stability) 주어진 설명이 입력, 모델 파라미터, 예측 확률의 작은 변동에 얼마나 강건한지 측정.
- Relative Input Stability (RIS) : 입력 데이터에 작은 변동이 있을 때 설명이 마나 안정적인지 측정함. 입력 데이터의 변화에 대해 설명이 얼마나 변하는지 평가.
- Relative Representation Stability (RRS) : 모델 파라미터의 작은 변화에 대해 설명이 얼마나 안정적인지를 측정함. 모델의 파라미터가 변화했을 때 설명이 얼마나 일관되게 유지되는지 평가.
- Relative Output Stability (ROS) : 출력 예측 확률의 작은 변화에 대해 설명이 얼마나 안정적인지를 측정함. 예측 결과가 변화했을 때 설명이 얼마나 일관되게 유지되는지를 평가함. - (Fairness) 다양한 그룹 간의 공정성을 평가
- 모든 지표값을 다수 그룹 (주로 많은 비율을 차지 하는 인구 집단) 과 소수 그룹 (상대적으로 적은 비율을 차지하는 인구 집단) 의 인스턴스에 대해 평균화하고 두 그룹의 추정치를 비교함. 두 그룹 간의 큰 차이가 나타나면, 이를 공정성의 부족으로 간주함.
2.4. Leaderboards
- 최초의 공개 XAI 리더보드 도입.
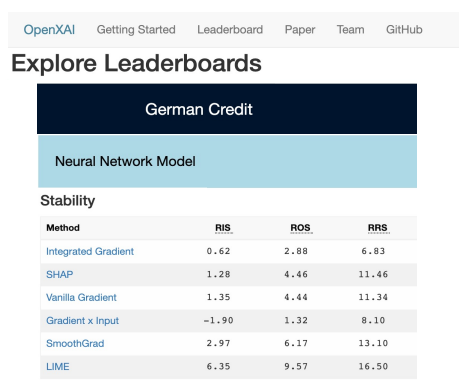
3. Benchmarking Analysis
- (Faithfulness) 생성된 설명과 GT 설명 사이의 유사성을 평가함.
- Vanilla Gradients, SmoothGrad, and Integrated Gradients 가 모든 데이터셋에서 PRA, FA, RA, RC 에서 완벽한 점수를 달성한 설명을 생성.
- 평균적으로 LIME 은 SA, SRA 에서 다른 방법보다 우수한 성과를 보임. 이때 gradient 기반 설명 방법들은 낮은 상대값을 기록함.
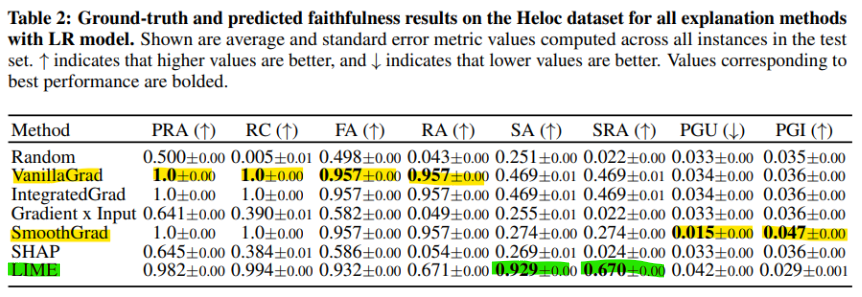
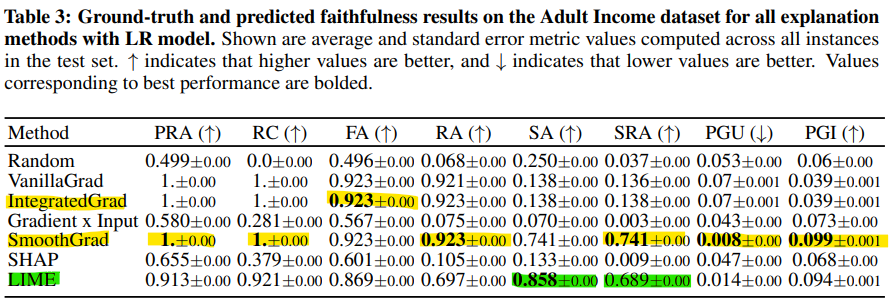
- (Predicitve Faithfulness) PGI 및 PGU 지표에 대한 결과를 보여줌.
- 전반적으로 SmoothGrad 설명이 기본 모델에 가장 충실하며 (LR 모델에서) 모든 데이터셋에서 우수한 성과를 보임.
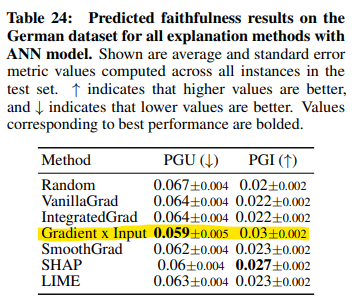
- But, ANN 모델에 대한 German dataset 의 결과에선, Gradient x Input 이 훨씬 더 신뢰성 있는 설명을 생성함을 보여줌. (Table 24)
-> 출력 설명이 서로 일치하는 경우가 많다는 것을 보여주며 벤치마킹의 필요성을 더욱 강조함.
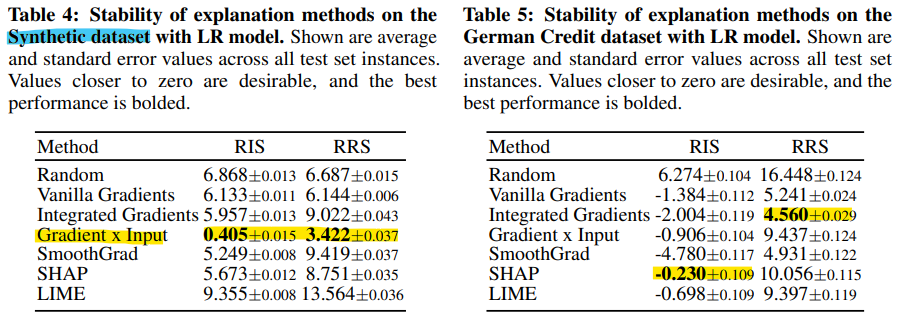
- (Stability) 상대적인 안정성은 데이터셋에 따라 상당히 달라지며 특정 설명 방법이 일관되게 가장 안정적이진 않았음.
- 합성 데이터셋에서는 Gradient x Input 이 평균적으로 다른 설명 방법들보다 RIS, RSS 에서 우수한 성과를 보임.
- But, 실제 데이터셋에서는 Gradient x Input 의 안정성이 크게 떨어짐.
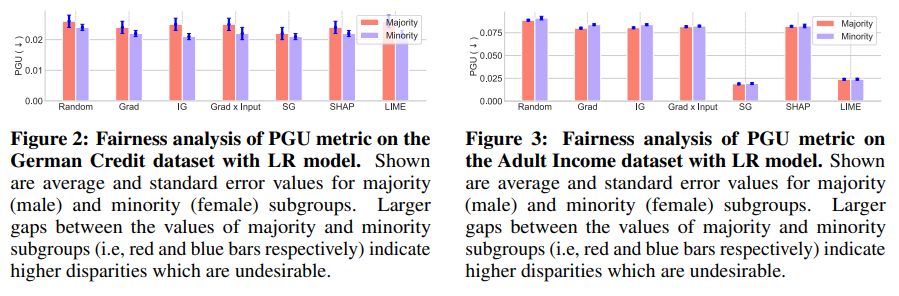
- (Fairness) 데이터셋의 다양한 하위 그룹에 대한 평균 지표 값을 계산하고 이를 비교함. 하위 그룹 간의 지표 값 차이가 클수록 불공정이 높다는 것을 나타냄. 일반성 (generality) 을 잃지 않기 위해 PGU 지표를 사용하여 결과를 제시함.
- Vanilla Gradients, Integrated Gradients, SmoothGrad 설명의 신뢰성에 불균형이 있음.
- Gradient x Input 방법은 두 데이터셋 모두에서 가장 적은 불균형을 보임.
>> 다양한 평가 지표 간의 트레이드오프를 시사함. 예를 들어, Gradient x Input 은 신뢰성 및 안정성 지표에서 성능이 떨어지지만 공정성 지표에서는 다른 방법들보다 우수한 성과를 보임. 이러한 트레이드오프를 고려해서 요구사항에 잘 맞는 설명 방법을 선택할 수 있음.
4. Conclusions
- post hoc explanations 이 다양한 중요한 애플리케이션에서 의사 결정자와 관련 이해관계자들을 지원하는 데 점점 더 많이 사용됨에 따라, 이러한 설명들이 신뢰할 수 있는지 확인하는 것이 중요해짐.
- OpenXAI는 XAI-ready 데이터셋, 최신 설명 방법의 구현, 평가 지표, 리더보드, 문서 등을 포함하는 오픈 소스 생태계로, post hoc explanations 의 평가에 대한 투명성과 협업을 촉진함.
- OpenXAI는 새로운 설명 방법을 벤치마킹하고 이를 프레임워크 및 리더보드에 통합하는 데 즉시 사용할 수 있음. 기존 및 새로운 설명 방법의 체계적이고 효율적인 평가와 벤치마킹을 가능하게 함으로써, OpenXAI는 XAI 분야의 새로운 연구를 알리고 가속화할 수 있음.
'Neuroscience > Artificial Intelligence' 카테고리의 다른 글
'Neuroscience/Artificial Intelligence' Related Articles
more



