Paper review | A review of Explainable Artificial Intelligence in healthcare
rrimyuu
2024. 7. 9. 16:40
1. Introduction
1.1. interpretability and explainability
해석 가능성 (interpretability) 은 시스템의 의사 결정 과정을 이해할 수 있는 규칙으로 제공하는 것을 의미함. 해석 가능성은 임상 채택 (clinical adoption) 을 가능하게 하고, 더 나은 정확성을 확인하며, 의사가 AI 알고리즘이 결정을 내리는 과정을 이해하고 완화할 수 있게 함으로써 오류나 편향과 관련된 위험을 줄임. 또한 해석 가능성은 윤리적 및 법적 요구 사항 준수를 보장하고, 정보에 입각한 동의와 환자 참여를 촉진하며, 지속적인 피드백을 장려함.
설명 가능성 (explainability) 은 인간이 AI 의사 결정 과정을 접근하고 이해할 수 있도록 하는 인터페이스를 만드는 데 중점을 둠. AI의 내부 의사 결정 기능을 풀어주는 인간이 이해할 수 있는 인터페이스를 만드는 것을 포함함. AI 기반의 의료 솔루션이 신뢰 (trust), 책임성 (accountability) 및 투명성 (transparency) 을 촉진하기 위해서는 의료 분야에서의 AI 해석 가능성이 필수적임.
기계 학습(ML) 모델을 설명하는 것은 인간 건강 시스템과 관련된 민감한 모델을 검증하는 데 필수적임. 의료 전문가들은 모델이 올바르게 훈련되고, 모델이 의존하는 매개변수가 자신의 지식과 일치하는지 확인할 필요가 있음. ex. ML 모델의 사후 분석 결과가 재채기가 암의 징후라고 결론지으면, 의사는 즉시 ML 모델이 신뢰할 수 없다는 것을 암시할 수 있음
딥 뉴럴 네트워크와 같은 복잡한 ML 모델은 대개 매우 고차원 데이터로 훈련되며 중요한 특징들을 포괄함. 이러한 훈련된 모델을 설명하면 물리학, 수학, 화학 등 다양한 분야의 전문가들에게 유익한 정보를 제공할 것임.
1.2. 사후 모델링 및 분석 (post-hoc modelling, and analysis)
모델 독립 방법 (model agnostic methods) : 범용적이며 구조나 학습 메커니즘에 관계없이 거의 모든 ML 모델에 적용할 수 있음. 강력한 독립적 접근법 중 하나는 sensitivity analysis (SA)으로, 입력 값을 변경하고 출력에서 발생한 변화를 관찰하여 입력 요인이 출력 예측에 미치는 기여와 영향을 밝히려고 시도함. SA 는 global 혹은 local 로 적용될 수 있음.
모델 특정 방법 (model-specific methods) : ML 모델에만 사용 가능. 학습된 심층 신경망을 이해하고 시각화하여 분석하기 위해 개발됨. Activation Maximization, DeConvNet, inversion, deepDream, feature visualization analysis, and DeepLift 등이 인기 있는 방법들임. optimization 과 backpropagation 을 통해 심층 신경망의 최종 결정에 미치는 기여를 찾고자 시도함.
인과관계 접근 방법 (causality approach) : 변수들 간의 인과관계를 발견하는 데 중점을 줌. 최근엔 DL 과 같은 블랙박스 구조의 투명한 모델 (transparent model) 과 표현력 (representation power) 을 갖춘 하이브리드 접근법 개발에 집중해옴. Contextual Explanation Network (CEN), Self-Explaining Neural Network (SENN), BagNet, and TabNet 등이 전형적인 예시임.
XAI 시스템 구현을 위한 연구 동기. 모델 투명성 증가, 책임성 개선, AI 시스템에 대한 신뢰 강화 등.
2. Explainable artificial intelligence methods
2.1. Feature-oriented methods
Shapley Additive exPlanation (SHAP) employs game theory to explain the outcomes of ML techniques.
Shapley values
Shapley value 는 게임이론을 바탕으로 각 플레이어의 기여도를 계산하는 것임. 게임이론 중 협력적(Cooperative) 게임 이론이 있는데, 이는 비협력적으로 게임을 했을 때 각 개인이 취하는 이득보다 협력적으로 게임을 했을 때 각 개인이 취하는 이득이 더 크다면 긍정적인 협동이 가장 최선의 선택지임을 가리킴.
즉 입력 변수별 Shapley value 는 ϕX1 = 3, ϕX2 = 2, ϕX3 = 2.
모든 Shapley value 합은 7 이며 이는 ⑧ - ① = 35 - 28 = 7 과 동일함.
이와 같은 Shapley value 계산 방식을 수식으로 정리하면 아래와 같음.
ϕi : 특정 변수의 Shapley value, S : 관심 변수가 제외된 변수 부분집합, i : 관심 있는 변수 집합, F : 전체 변수의 부분 집합.X1 1개 사용하는 경우 관련 기여도X1 포함 변수 2개 사용하는 경우 관련 기여도
모든 변수 사용하는 경우 관련 기여도기여도 계산 및 가중치 적용 관련 값각 케이스별 가중치 계산 과정가중치 공식Shapley Value 계산
Shap values
글로벌 변수 중요도 뿐만 아니라 개별 예측값에 대한 각 변수들의 영향력을 모형 클래스에 상관없이 (model-agnostic) additive 하게 배분하는 방식임. 이때 영향력을 측정하는 값으로 Shapley values 를 사용함. 변수 중요도로써 가져야 할 바람직한 성질 (local accuracy, missingness and consistency) 을 가지고 있어 인간이 생각하는 것과 유사한 해석을 제공함.
Class Activation Maps (CAM)
CNN 구조에서 Input → Conv Layers → FC layers 과정 중 FC-layer 층 에서 flatten 시키면 위치 정보를 잃어버리게 됨. 따라서 classification 정확도가 높아도, CNN이 무엇을 보고 특정 class 로 분류한 것인지 모르게 됨. FC layer 대신 Global Average Pooling 을 적용해 특정 클래스 이미지의 Heat map 을 생성하여 CNN 이 어떻게 이미지를 특정 클래스로 예측했는지 알 수 있음.
Global Average Pooling 을 통해 각각의 feature map 마다 그 맵에 포함된 모든 원소 값의 평균합을 진행함. 결과적으로 그 층으로 들어오는 feature map의 channel 수와 동일한 길이의 벡터를 얻게 됨. GAP 층을 지나고 FC layer 을 붙여서fine-tuning을 진행함. feature map f_k 에 대한 가중치 w_k 를 곱해주면 feature map 갯수 만큼 heatmap 을 뽑을 수 있음. 이 heatmap 이미지를 Pixel-wise sum 을 진행하면 하나의 CAM heatmap 을 얻을 수 있음. >> 마지막 레이어에서 발생된 feature map 을 Global Average Pooling 해서 가중치를 얻어내고 이 가중치에 featuer map 을 곱해주면 heatmap 을 얻을 수 있는데, 이 heatmap 을 pixel wise sum 하면 이미지에서 어떤 파트를 주로 봤는지 알 수 있다. (CAM heatmap)
convolution layer 를 통과한 featuer map 은 input image 의 전체 내용을 함축하고 있음. CAM 은 마지막 convolution layer를 통과해 나온 feature map 에 대해서만 CAM을 통하여 Heat map 추출이 가능함.
conv feature maps -> global average pooling -> softmax layer 순으로 구성되며 softmax layer 를 통해 Sc (CAM score) 를 얻음. 그렇기 때문에 softmax layer 전에 featuer map 을 얻어야 하며 이는 특정 CNN 구조에만 적용 가능함을 시사함. 또한 weight 를 얻기 위하여 CNN 학습이 필수적으로 필요함.
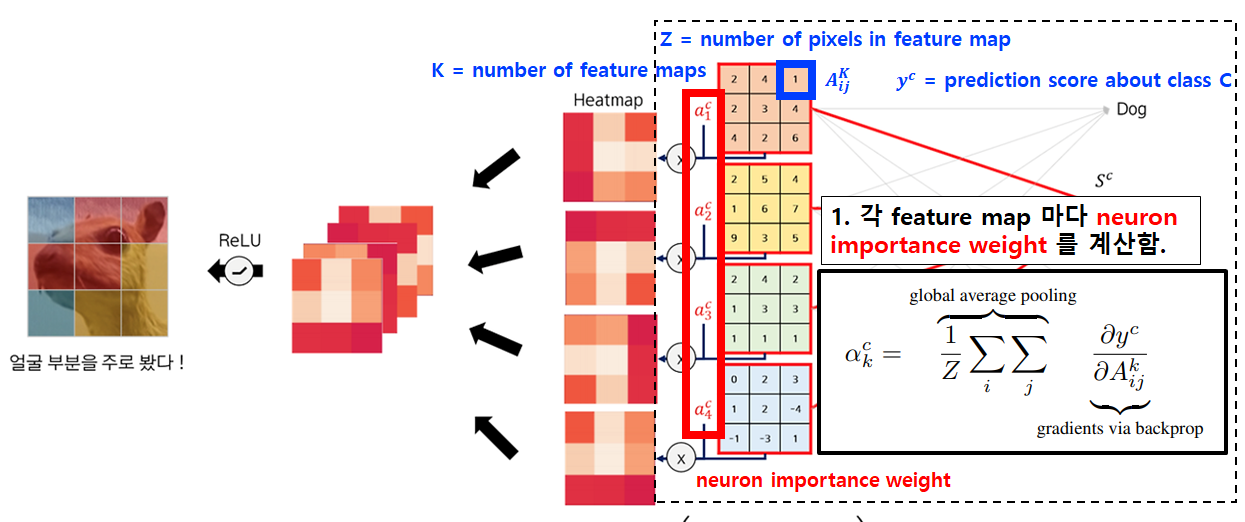
CAM 의 단점을 보완하기 위하여 나온 Grad-CAM 은 기존 CNN 모델의 구조 변화가 없으며, Global Average Pooling 없이 FC layer가 두 개 존재함. 각 feature map 에 곱해줄 weight 를 미분 (gradient) 을 통해 구하기 때문에 기존 CNN의 학습이 필요 없게 됨. 여기서 gradient 는 class C 에 대해 input 값이 주는 영향력이라고 할 수 있음.
k=6 개의 feature map 을 이용해 y=2, 아이언맨으로 분류한다면, class C 에 대한 점수 y_c 을 softmax 로 거쳐지기 전에 각 원소로 미분함. 이 미분값은 feature map 의 원소가 특정 class 에 주는 영향력이 됨. >> 각 feature map 에 포함된 모든 원소의 미분값을 더하여 뉴런 중요 가중치값 a 를 구하면, 이 a 는 해당 feature map 이 특정 class 에 주는 영향력이 됨.
neuron importance weight (a_k^C) Gradient via backprop (A_ij^k) 와 class C 에 대한 예측 (y) 스코어 (y^C) 를 구함. 이는 class C 를 예측하는 데 각 레이어 (마지막 레이어 아니어도 됨) 에서의 feature map 의 각 원소 (i, j 위치 픽셀/ 좌표) 이 주는 영향력을 구하는 것임. (= y^C 가 나오는 데 해당 feature map 내 원소가 얼마나 중요한 역할을 미치는지를 의미함.) i, j 위치 원소에서 구한 gradient 를 모두 더하고 해당 feature map 원소 개수 (Z) 로 나눔. https://arxiv.org/pdf/1610.02391
K개 feature map (A^k) 와 neuron importance weight 를 곱해 weight sum of feature map (linear combination) 를 구함. 그런 다음 ReLU 를 취해 최종적인 Grand-CAM 에 의한 heatmap 을 출력함. (L_Grand-CAM^C) >> ReLU 를 사용하는 이유는 positive 영향을 주는 feature map 에 집중하기 위함. class C 에 대한 예측 스코어 (y^c) 를 증가시키기 위해 증가되어야 하는 원소 (A_ij^k) 를 구하는 것임.
Global Attribution Mappings (GAMs)는 다양한 집단에 걸친 신경망 예측을 설명하는 데 중요한 도구로, 특히 다양한 수준의 세분성에서 뚜렷한 하위 집단을 식별하고 분석하는 데 큰 이점을 제공합니다. 이러한 매핑은 서로 다른 특성 간의 복잡한 관계를 포착하여 쌍별 순위 거리 행렬을 효과적으로 생성합니다. 이 과정은 K-메도이드 클러스터링을 사용하여 유사한 지역 특성을 그룹화하는 방법을 포함하며, 이는 매핑의 정확성을 높여줍니다.
CNN은 Input으로부터 layer가 깊어질주록 high-level의 feature를 추출한다. 낮은 layer에서는 Edge, Comer, Color와 같은 구체적인 정보들(Low-level Features)을 추출하고, 깊은 layer에서는 Object의 일부분이나 전체 Object처럼 사람이 직관적으로 볼 수 있는 정보들(High-level Features)를 추출한다. Image classifier와 같은 많은 시스템에서 high-level feature보다는 low-level feature를 사용하는데, 이 논문에서는 사람이 직관적으로 이해할 수 있는 특징 또는 사용자가 직접 정의한 특징을 Concept이라고 정의하고 이 Concept을 기반으로 이미지를 이해하는 법(CAV: Concept Activation Vector)을 소개한다.
예를 들어, 신경망이 말과 얼룩말 사진을 구별하도록 훈련되었다고 가정합니다. CAT를 사용하면 몸 줄무늬가 있는 동물이 얼룩말로 분류되는 데 기여하는 수준을 측정할 수 있습니다.
https://hellopotatoworld.tistory.com/21
2.4. Surrogate models
Local interpretable model-agnostic explanation (LIME)
Local interpretable model-agnostic explanation (LIME) 은 해석 가능한 대리 모델을 사용하여 기계 학습 모델의 지역적으로 최적의 설명을 구축합니다. 복잡한 블랙 박스 모델의 작동 메커니즘을 설명하는 것은 어렵지만, 특정 입력 샘플에 대해 그들의 동작을 설명하는 것은 가능합니다. LIME 방법은 주어진 입력 샘플의 일부를 수정하여 원본 입력과 유사하지만 정확히 같지는 않은 데이터 집합을 생성하는 것으로 시작합니다. 이러한 왜곡은 입력 샘플의 성격에 따라 달라집니다. 예를 들어, 이미지 입력의 경우 일부 부분을 회색으로 대체하여 왜곡된 대응 샘플을 얻을 수 있습니다.
permute data: 각 observation에 대해, 피처 값을 permute하여 새로운 fake dataset을 만듭니다.
calculate distance between permutation and original observation: 위에서 생성한 fake data와 original data의 distance(즉, similarity score)를 계산하여, 원래 데이터와 새로 만든 데이터가 얼마나 다른가를 측정합니다. (이를 나중에 weight로 사용) https://myeonghak.github.io/xai/XAI-LIME(Local-Interpretable-Model-agnostic-Explanation)-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98/노란색 원: fake dataset; 보라색 원 : 해석하고자 하는 포인트; 검정색 선 : 로지스틱 회귀 모형을 통한 선형 결정경계
make prediction on new data using complex model: 블랙박스 모델을 사용해 생성한 데이터의 라벨을 예측합니다.
pick m features best describing the complex model outcome from the permuted data: 블랙박스 모델의 결과로 나온 클래스의 likelihood를 maximize하는, 최소한의 피처 m개를 찾아 냅니다. 이 과정은 매우 중요한데, 수백 개의 피처를 사용해 예측을 수행할 경우에도 몇 개의 중요한 피처만을 남겨낼 수 있기 때문입니다. 이 몇 개의 피처들은 예측을 도출해내기 위해 필요한 정보가 가장 많은(informative) 피처라고 생각할 수 있습니다.
Fit a simple model to the permuted data with m features and similarity scores as weights: m개의 피처들을 뽑아서, 생성한 데이터에 설명 가능한 linear model과 같은 알고리즘으로 학습하고, 가중치와 기울기를 구합니다. 2)에서 구한 유사도를 weight로 사용하여 모델을 fitting합니다.
Feature weights from the simple model make explanation for the complex models local behavior: 여기서 구한 모델의 기울기(coef)는 local scale에서 해당 observation에 대한 설명이 됩니다.
레이어 단위 관련성 전파 기술 (LRP)는 NN (Neural Network) 모델에서 결과를 역추적해 입력 데이터의 개별 feature 에 대한 기여도를 계산하는 방법임. DL 모델의 예측 결과를 분석하여 입력 데이터의 개별 feature에 대한 기여 점수를 도출하는데 사용됨. 각 입력에 대한 기여 점수는 결과 클래스 노드의 클래스 점수를 입력 계층으로 역전파하여 계산됨.
이 접근 방식은 히트맵을 생성하여 어떤 픽셀이 모델의 예측에 어느 정도 기여했는지에 대한 통찰력을 제공함. 결과적으로 LRP는 네트워크의 선택에 긍정적인 영향을 미치는 변수를 강조함.
(Relevance Propagation) relevance score를 출력단에서 입력단 방향으로 top-down 방식으로 기여도를 재분배 하는 방법. LRP의 기본적인 가정 및 작동 방식은 다음과 같음. - 각 뉴런은 어느 정도의 기여도(certain relevance)를 갖고 있음. - 기여도는 top-down 방식으로 각 뉴런의 출력단에서 입력단 방향으로 재분배 됨. - (재)분배시 기여도는 보존됨.https://goatlab.tistory.com/entry/LRP-Layer-Wise-Relevance-Propagation
(Decomposition) input의 각 feature가 결과에 얼마나 영향을 미치는지 해체하는 방법 (ex) Image x를 "cat"으로 분류하는데 각 hidden layer에서 계산한 기여도를 토대로 해당 input image x의 feature들이 모델을 어떻게 받아들였는지 히트맵으로 도식화 - Positive 영향을 준 feature : 빨강 - Negative 영향을 준 Feature : Blue >> 이마, 코, 입 주변의 pixel들이 결과에 영향을 많이 준 것을 확인할 수 있음.
https://hellopotatoworld.tistory.com/17
3. Explainable Artificial Intelligence tools
(MIT - ELI5 라이브러리) ML 모델을 시각화하고 디버깅하기 위한 Python 라이브러리임. ELI5는 Scikit-learn, Keras, LightGBM 등 다양한 ML 프레임워크를 지원함.
(IBM - AI Fairness 360) ML 모델과 데이터 세트에서 편향 탐지 및 완화 프로세스를 용이하게 하기 위해 개발된 오픈소스 라이브러리임. 이 라이브러리는 Python과 R에서 사용할 수 있음.
(Google - "What If Tool"(WIT)) 필요한 코딩을 최대한 줄이면서 훈련된 ML 모델 동작에 대한 시각적 탐색을 제공함. Jupyter/Colaboratory/Could AI 노트북, TensorBoard 등 여러 플랫폼과 통합할 수 있음.
(H2O.ai) H2O 플랫폼은 다양한 비즈니스 문제에서 AI 모델의 개발 및 배포를 가속화하는 것을 목표로 함. H2O는 사용자에게 AI 모델의 기술적 세부 정보를 숨겨 코드를 작성하지 않고도 AI 애플리케이션을 개발할 수 있음.
(Distill) 신경망 의사결정 프로세스 분석을 개선하고자 다양한 해석 기술을 결합하는 데 목표를 둔 연구임. 기능 시각화, 귀속 및 차원 감소와 같은 해석 방법의 보완적 역할을 활용하여 이를 통합 인터페이스의 빌딩 블록으로 처리함.
(Oracle - Skater) 전역적 및 지역적으로 훈련된 모델의 동작을 분석하기 위한 Python 라이브러리임. 전역 시나리오에서 분석은 전체 데이터 세트에 대한 추론을 기반으로 수행됨. 지역 시나리오에서 분석은 단일 샘플에 대한 예측을 기반으로 수행됨.
4. Explainable AI for decision makers
AI 기반 결과는 고위험 의료 선택을 할 때 잠재적으로 심각한 결과를 초래할 수 있음. AI 모델의 전형적인 특징으로 높은 복잡성, 방대한 양의 데이터 세트, ML 모델의 성능을 높이는 데 필요한 엄청난 처리 능력이 있음. 이러한 모델이 더 복잡해질수록 작동, 데이터 처리 및 의사 결정을 파악하기가 더 어려워지므로 이를 불투명 모델 또는 블랙박스 모델이라고 함.
이러한 문제를 해결하기 위해 (1) 블랙박스 모델 설명, (2) 블랙박스 모델 평가, (3) 결과 설명, (4) 투명한 블랙박스 모델 구축 등 열린 블랙박스 모델을 표현하기 위한 분류법이 제안되었음. 많은 과학자들은 XAI가 이해 관계자 간에 AI 시스템에 대한 신뢰와 이해를 구축하는 데 도움이 되기 때문에 XAI가 의료 산업에서 AI를 배포하는 데 도움이 됨.
의료와 같은 중요한 도메인에서 AI를 도입하는 데 있어 근본적인 과제는 모델이 어떻게 기능하는지에 대한 이해가 부족하기 때문에 모델 출력을 신뢰하기 어렵다는 것임. 이러한 신뢰는 알고리즘의 개발 프로세스에 대한 더 깊은 통찰력을 얻음으로써 상당히 강화될 수 있으며, 이를 통해 AI 애플리케이션에서 생성된 결과에 대한 확신을 높일 수 있음. 중요한 필요성에도 불구하고, 특히 의료 분야에서 AI를 의사 결정 프로세스에 효과적으로 통합하는 데 필요한 특정 유형의 정보를 식별하는 데 초점을 맞춘 연구는 거의 없었음.
따라서, 의학에 구현된 투명한 AI 방법론은 매우 중요하며, 정확한 진단 및 예측과 함께 AI가 생성한 결정을 설명하고 해석할 수 있는 역량을 보장함. 의료 분야에서 투명한 AI를 개발하는 것은 의료 분야에서 정확성, 해석 가능성 및 윤리적 AI 활용을 향한 중요한 진전을 나타냄.
5. Applications of explainable AI in healthcare
(SPECT DaTscan) 도파민 작용 영상 기술이 파킨슨병의 조기 진단을 위해 분석되었음. 이때, LIME 기술은 동일한 적절한 추론을 통해 주어진 DaTscan에서 파킨슨병을 정확하게 분류하는 데 사용되었음.
(급성 중증 질환 감지) 조기 경고 점수 시스템이 제안되었음. 이 시스템은 SHAP 기술을 사용하여 전자 건강 기록 데이터 정보로 예측을 설명할 수 있었음.
(뇌졸중 후 병원 퇴원 처분을 예측하기 위한 ML) 선형 회귀를 기준 모델로 선택하여 블랙박스 모델과 비교했음. LIME 기술을 사용하여 모델의 필수 특징을 식별했음.
(알츠하이머병 식별 및 진행 예측을 위한 모델) 첫 번째 계층은 랜덤 포레스트 (RF) 를 활용하여 초기 단계의 Alzheimer's Disease (AD) 환자를 분류함. 두 번째 이진 분류 계층은 초기 진단 후 3년 이내에 경미한 인지 장애(MCI)가 AD로 진행될 가능성을 예측하기 위해 수행됨. 각 계층에서 SHAP 기술이 모델 추론에 대한 설명을 제공하는 데 사용됨.
(파킨슨병 감지 모델) SHAP 기술이 포함된 GBT(Gradient Boosted Trees), 신경망 등이 포함되어 85%의 정확도를 달성하고 EHR 시스템에서 누락된 데이터로 인한 과제를 해결했음.
6. The challenge of interpretability in healthcare
6.1. User-Centric explanations
복잡한 ML 모델을 분석하려면 고급 수학과 통계에 대한 배경 지식이 필요함. ex. 의료 분야에서 XAI를 적용하는 또 다른 문제는 ML 전문가들이 수학적 설명 출력을 선호하는 반면, 임상의들은 시각적 형태의 설명을 선호하기 때문임. 이러한 요구는 XAI 방법의 출력 형식에 제약을 가함.
지금까지 의료 시스템은 의료 분야에서 ML 모델을 성공적으로 배포하기 위한 설계 및 기능 요구 사항을 충족하지 못했음.
최종 사용자의 해석 가능성에 대한 요구는 복잡한 블랙 박스 모델의 개발과 인간이 이해할 수 있는 설명 사이의 격차를 넓힘. (최종 사용자가 ML 모델의 결과를 이해할 수 있기를 원하지만, 이러한 요구가 복잡한 블랙 박스 모델의 개발과 인간이 이해할 수 있는 설명 사이에 갈등을 일으킨다는 의미임) - 사용자의 요구와 기대를 제품 설계 지원과 일치시키기 위해 최종 사용자를 ML 모델 개발에 참여시켜야 함. - XAI 방법이 그럴듯한 설명을 제공하더라도, ML 모델의 오류 원인을 이해하고 분석할 수 있는 사람은 오직 임상의들임. 따라서 ML 전문가들은 항상 모델을 디버깅하고 개선하기 위해 임상의에 의존해야 함.
ML 모델을 더 투명하게 만들면 목표를 달성하는 데 있어 덜 효율적이게 될 가능성이 높음. 고성능 모델이 복잡한 상호 연결이 많은 여러 레이어로 구성되어 있기 때문임. 따라서 수백만 개의 샘플에 대한 학습 과정을 추적하는 것은 거의 불가능함.
설명 가능한 인공지능(XAI) 방법은 ML 모델 출력과 관련된 영역만 강조할 뿐, 그 영역의 관련성을 유발한 특징을 결정하지는 않음.
모델을 투명하게 만들기 위한 상당한 노력이 기울여지고 있지만, 제공된 설명의 적절한 평가는 여전히 해결되지 않은 문제임. 게다가 일부 연구자들은 XAI 방법이 오해의 소지가 있다고 생각하여 그 신뢰성에 의문을 제기하고 있.
>> 설명 가능한 AI의 발전은 의료 분야에서 Sustainable Development Goals (SDGs) 를 달성하는 데 크게 기여할 수 있는 잠재력이 있음. XAI 방법론을 모든 연령대의 건강한 삶을 보장하고 웰빙을 증진하는 것을 목표로 하는 SDG 3과 일치시킴으로써, 진단 정확성, 치료 효과 및 전체 의료 서비스 제공을 향상시킬 수 있음.
6.2. Performance vs. transparency tradeoff
모델의 복잡성과 정확성 간의 균형을 맞추는 것이 중요함. 보편적으로 설명 가능성은 AI 시스템의 성능과 반비례함. 모델을 아래 3가지로 구분할 수 있음.
블랙 박스 AI (DL 및 앙상블) : 이러한 경우 투명하지 않아 결정에 대한 수용 가능한 근거를 제공하기 어렵고 최종 사용자의 신뢰를 얻기 힘듦.
그레이 박스 AI (통계) : 투명성과 설명 가능성의 중간 균형을 유지함.
화이트 박스 AI (그래픽 모델, 선형 모델, 규칙 기반 모델, 의사 결정 트리) : 설명 가능성이 높지만 성능이 낮음.
>> 모델의 이해 가능한 패턴 식별 능력과 데이터를 정확히 맞추는 유연성 간의 균형을 필요로 합니다.
6.3. Balancing requirements of interpretability
의료 분야에서 해석 가능한 ML 시스템에 대한 이상적인요구 사항이 명확히 제시되어야 함. 일반적으로 ML 설명은 모델의 soundness (타당성) 혹은 optimality (최적성) 과 같은 사용자가 이해할 수 있는 능력과 관련이 있음. 이외에도 모델의 설명 범위를 로컬 수준과 글로벌 수준에서 모두 다루는 것이 중요함. 도전 과제는 모델의 타당성, 이해, 범위를 보장하고 블랙 박스 및 그레이 박스 AI 모델의 작동 메커니즘에 대한 신뢰성을 만족시키는 것임.
6.4. Assistive intelligence
ML 알고리즘의 궁극적인 목표는 다양한 응용 분야에서 인간을 의사 결정 과정에서 제거하는 것임. 그러나 의료와 같은 안전이 중요한 응용 분야에서는 의사 결정을 ML 시스템에 완전히 맡길 수 없음. 따라서 인간 전문가의 감독이 항시 필요함. ML 방법은 인간 전문가가 의료 데이터를 분석할 때나 유용한 지식을 추출하는 데 가속화하는 개념으로 의료 보조 역할을 해낼 수 있음. 이때 의료 시스템은 정확한 데이터를 필요로 하므로 인간 참여 프레임워크와 XAI 메커니즘이 필요함.
7. Conclusion
DL 등장으로 의사결정 및 예측 알고리즘에서 높은 성능 달성. 하지만 알고리즘의 불투명한 특성으로 인해 의사결정 과정을 이해하는 데 어려움을 초래하고 있음. 이러한 불투명성은 XAI 분야 성장을 촉진함.
XAI 는 AI 학습 메커니즘을 명확히 할 뿐만 아니라 DL 성능을 개선하는 데도 중요한 역할을 하고 있음.
추후 의료 AI에서는 사후 설명이 필요 없는 자체 설명 기술 개발을 우선시해야 함. 이러한 접근은 의료 전문가 및 환자 모두 이해할 수 있는 투명한 AI 솔루션으로 이어질 수 있음. 사용자가 치료 계획의 근거를 이해할 수 있다면 AI 지원 애플리케이션의 신뢰성과 일관성이 향상될 것임.